In the rapidly evolving landscape of artificial intelligence, Retrieval-Augmented Generation (RAG) has emerged as a pivotal technique, combining the strengths of information retrieval and text generation to produce more accurate and contextually relevant outputs. To further refine RAG systems, integrating user intent classification and emphasizing contextual understanding are essential. Additionally, leveraging Small Language Models (SLMs) and fine-tuning methodologies can significantly enhance the precision and relevance of generated content.
Understanding Retrieval-Augmented Generation (RAG)
RAG is a framework that enhances the capabilities of Large Language Models (LLMs) by incorporating external knowledge sources. This integration allows models to access up-to-date and domain-specific information, thereby improving the quality of generated responses. The RAG process typically involves:
- Retrieval: Identifying and fetching relevant documents or data from external sources based on the user’s query.
- Augmentation: Incorporating the retrieved information into the model’s input to provide context.
- Generation: Producing a response that combines the model’s internal knowledge with the augmented external data.
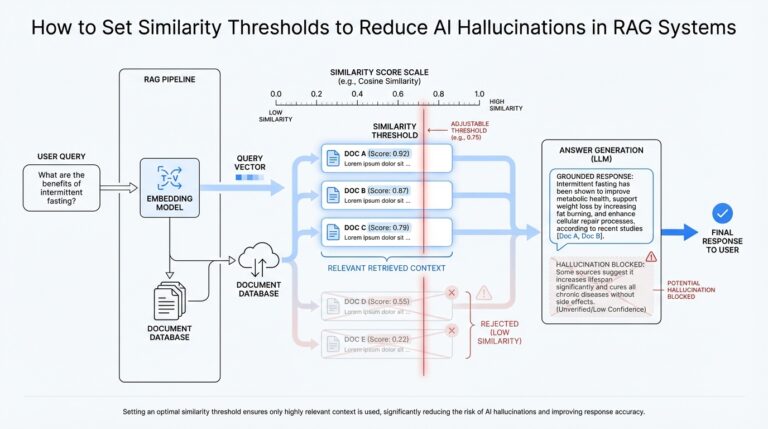
This approach addresses the limitations of LLMs, such as outdated information and hallucinations, by grounding responses in factual and current data.
The Role of User Intent Classification in RAG
A critical aspect of enhancing RAG systems is accurately interpreting the user’s intent. By classifying queries based on intent, models can tailor their retrieval and generation processes to better align with user expectations. Implementing an intent classification model involves:
- Training a Classifier: Utilizing machine learning techniques to categorize user queries into predefined intents, such as fact-based lookup, summarization, translation, or question answering.
- Zero-Shot Classification: Employing models capable of categorizing queries without task-specific training, enabling flexibility in handling diverse user inputs.
By understanding the user’s intent, the system can select the most appropriate retrieval and generation strategies, leading to more accurate and relevant responses.
Emphasizing Contextual Focus
Context is paramount in generating meaningful and coherent responses. Incorporating contextual information involves:
- Multi-Turn Dialogue Handling: Managing conversations that span multiple interactions, ensuring the model maintains awareness of the dialogue history to provide consistent and contextually appropriate responses.
- Adaptive Retrieval: Dynamically selecting relevant information based on the evolving context of the conversation, allowing the model to adjust its responses as new information becomes available.
Focusing on context ensures that the generated content is not only accurate but also coherent and aligned with the user’s ongoing interaction.
Leveraging Small Language Models (SLMs) and Fine-Tuning
While Large Language Models offer extensive capabilities, they can be resource-intensive. Small Language Models (SLMs) present a more efficient alternative, especially when fine-tuned for specific tasks. The advantages of utilizing SLMs include:
- Resource Efficiency: SLMs require less computational power, making them suitable for deployment in environments with limited resources.
- Task Specialization: Fine-tuning SLMs on domain-specific data enables them to perform specialized tasks with high accuracy, often matching or exceeding the performance of larger models in those areas. Data Science Central
Fine-tuning involves training a pre-trained model on a specific dataset to adapt it to particular tasks or domains. This process enhances the model’s ability to generate content that is both accurate and contextually relevant to the user’s needs.
Implementing Enhanced RAG Systems: A Step-by-Step Approach
To develop a RAG system that effectively integrates user intent classification, contextual focus, and leverages SLMs with fine-tuning, consider the following steps:
- Data Collection and Preparation: Gather and preprocess a diverse dataset that includes various query types and corresponding intents. Ensure the data is representative of the target domain.
- Intent Classification Model Development: Train a classifier capable of accurately categorizing user queries into predefined intents. Utilize techniques such as zero-shot learning to handle a wide range of query types.
- Context Management Mechanism: Implement a system to track and manage the context of multi-turn dialogues, enabling the model to maintain coherence across interactions.
- SLM Selection and Fine-Tuning: Choose an appropriate Small Language Model and fine-tune it on the domain-specific dataset to enhance its performance on targeted tasks.
- Integration of Components: Combine the intent classifier, context management system, and fine-tuned SLM into a cohesive RAG framework. Ensure seamless interaction between components for efficient retrieval and generation processes.
- Evaluation and Iteration: Continuously evaluate the system’s performance using relevant metrics and user feedback. Iterate on the design and training processes to address any identified shortcomings and improve overall effectiveness.
Conclusion
Enhancing Retrieval-Augmented Generation systems by incorporating user intent classification and emphasizing contextual understanding leads to more accurate and relevant outputs. Leveraging Small Language Models and fine-tuning techniques further optimizes performance, offering efficient and specialized solutions. By systematically implementing these strategies, developers can create advanced RAG systems that effectively meet user needs and adapt to various domain-specific challenges.