Machine learning (ML) has become a powerful tool across industries, offering unprecedented capabilities to automate, analyze, and predict. However, deploying ML projects into production involves a level of complexity that often surprises even experienced practitioners. In this comprehensive guide, we explore the key elements of deploying machine learning systems, common challenges, and best practices to ensure successful implementation and maintenance.
Understanding Machine Learning Applications
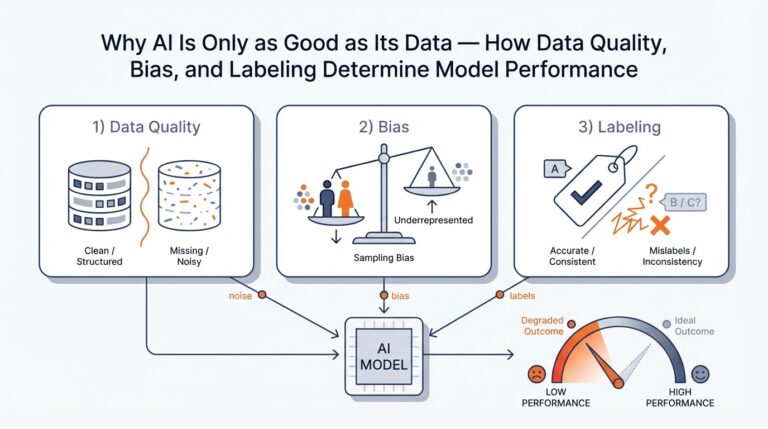
A typical machine learning application consists of three key components: data, model, and code. For instance, consider a bank’s decision to adopt ML to detect fraudulent credit card transactions. This transition from traditional rule-based systems to an ML-driven application introduces a host of new considerations and challenges.
Components of an ML System
- Data Management: Preparing data for training ML models is a critical step. This includes data collection, cleaning, and feature engineering.
- Model Learning: This phase involves selecting and training models, often requiring multiple iterations to achieve optimal performance.
- Model Verification: Ensures the model meets functional and performance requirements.
- Model Deployment: Integrating the trained model into production, including post-deployment monitoring and updates.
These tasks are cyclical, as new data and requirements continuously emerge. Maintaining an ML system over time requires a disciplined approach to ensure operational excellence.

MLOps: Bridging the Gap Between Development and Operations
The concept of MLOps (Machine Learning Operations) borrows from DevOps to streamline the ML lifecycle. Continuous delivery, automation, and feedback loops are essential to achieving reliable production deployments. MLOps addresses the unique challenges of ML systems, such as data drift, concept drift, and maintaining reproducibility.
Key Components of MLOps
- Unified Release Cycle: Brings together ML engineers and software developers to collaborate on integrating and deploying models.
- Automated Testing and Versioning: All artifacts in the ML pipeline require version control and automated testing.
- Continuous Delivery with Small Increments: Incremental updates to the ML model allow for greater visibility and control.
- Reproducibility and Reliability: Automation and rigorous processes ensure consistent outcomes.
Addressing Technical Debt in ML Systems
Technical debt is a significant concern in ML systems, as highlighted in the 2015 paper “Hidden Technical Debt in Machine Learning Systems.” This debt arises from various sources, including:
- Data Defects: Unlike code defects, data defects lack standardized tooling for detection, making them challenging to identify.
- Analysis Debt: ML systems often influence their own behavior, leading to unexpected outcomes.
- Anti-Engineering: A small fraction of the code in ML systems is dedicated to learning or prediction, with the rest often suffering from poor design patterns.
- Configuration Debt: A wide range of configurable options increases the potential for mistakes.
- Reproducibility Debt: ML systems must maintain reproducibility across various iterations and updates.
MLOps aims to mitigate these debts by implementing a robust framework for deploying and maintaining ML systems.
Challenges in Deploying Machine Learning Models
Deploying ML models presents several challenges, falling into two main categories:
- Statistical and Machine Learning Challenges: Addressing issues like model accuracy, overfitting, and hyperparameter tuning.
- Software Engineering Challenges: Ensuring scalability, system integration, and compatibility with existing infrastructure.
Navigating these challenges requires a comprehensive approach, including proper planning, rigorous testing, and continuous monitoring.
Navigating Concept Drift and Data Drift
Concept drift and data drift are common challenges in ML deployments. Concept drift refers to changes in the underlying relationships within the data, while data drift involves changes in the data distribution. For instance, the COVID-19 pandemic caused significant shifts in consumer behavior, affecting credit card fraud detection systems.
Understanding and addressing drift requires continuous monitoring and retraining of ML models to ensure they remain accurate and effective.

Strategies for Deploying Machine Learning Systems
Deploying ML systems involves several deployment patterns, each with its unique benefits:
- Shadow Mode Deployment: Runs the ML system alongside human decision-makers without affecting outcomes. This approach allows for comprehensive testing and validation before granting the ML system decision-making authority.
- Canary Deployment: Involves rolling out the ML system to a small fraction of traffic, allowing for gradual monitoring and adjustment.
- Blue-Green Deployment: Enables seamless transitions between different versions of a prediction service, facilitating easy rollback if needed.
These deployment patterns help mitigate risks and ensure a smooth transition from proof of concept to production.
Monitoring Machine Learning Systems
Monitoring is crucial to ensure ML systems meet performance expectations. The standard approach involves using dashboards to track system metrics over time. Key metrics to monitor include:
- Software Metrics: Memory usage, compute resources, latency, and server load.
- Statistical Metrics: Statistical health and performance of the ML system.
- Output Metrics: Coarse metrics like click-through rate (CTR) to ensure robustness.
Choosing the right set of metrics and establishing appropriate thresholds for alarms and notifications helps maintain system stability and performance.
Conclusion
Deploying machine learning systems into production is a complex journey that requires careful planning, rigorous testing, and continuous monitoring. By embracing MLOps principles, understanding technical debt, and utilizing appropriate deployment patterns, organizations can navigate the challenges and achieve successful ML deployments.
As the ML community continues to learn from real-world deployments, this comprehensive guide aims to provide valuable insights and best practices for ensuring the success of your ML projects.